
개요
호텔 예약 플랫폼 프로젝트를 진행하면서 얻은 Spring Batch 경험을 공유하는 시리즈를 시작한다.
이 시리즈는 대규모 데이터를 안정적으로 처리하기 위한,
배치 Job 설계부터 시작해서 성능 병목을 진단하고 개선해 나가는 과정을 담을 예정이다.
먼저, 이 글에서는 배치로 해결하고자 하는 문제에 대해 얘기해보려한다.
단순히 "성능 좋은 배치 만들었다"가 아니라,
왜 이 배치가 필요했고, 어떤 비즈니스 문제를 풀려고 했는지 그 맥락부터 짚어보는 게 중요하다고 생각했다.
주제는 "객실 가용성(RoomAvailability) 자동 생성" 이다.
이 글이 앞으로 이어질 기술 이야기의 단단한 발판이 되길 바란다.
문제 인식: 핵심은 '언제, 어떤 방을, 얼마에 예약할 수 있는가'
아래와 같이 호텔 예약 플랫폼을 생각해보자.

고객 입장에서 가장 중요한 건
"원하는 날짜에, 어떤 방을, 얼마에 예약할 수 있느냐"이다.
이 정보를 시스템에서는 RoomAvailability 데이터라고 부르기로 했다.
특정 날짜와 특정 객실 타입을 기준으로, 예약 가능 개수와 가격 정보를 담는 데이터다.
아래 ERD를 보면 이 데이터(room_availability)가 다른 데이터와 어떻게 관계 맺는지 알 수 있다.
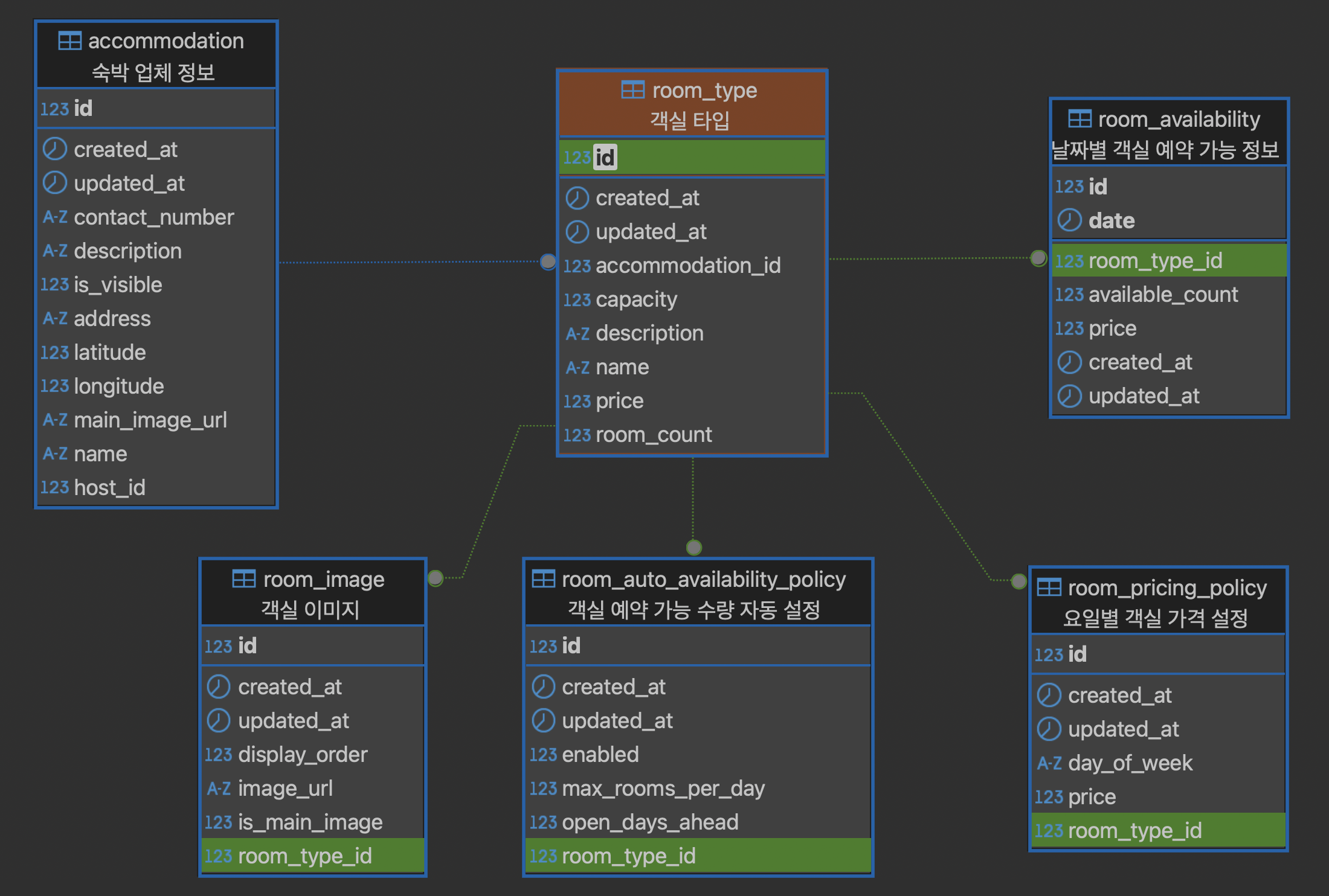
ERD에서 볼 수 있듯 room_availability는 room_type(객실 정보)과 date(날짜)를 기준으로 생성되며,
이는 숙박 업체 측이 설정하는
room_auto_availability_policy(자동 예약 오픈 정책)와 room_pricing_policy(가격 정책)의 영향을 받는다.
만약 이 RoomAvailability 데이터가 자동으로 관리되지 않으면 심각한 문제가 생긴다.
- 숙박 업체(사장님)의 고통: 매일 수백, 수천 개의 객실에 대해 앞으로 180일 치 예약 가능 수량과 가격을 직접 입력해야 한다.
이건 사람이 할 짓이 못 된다. 실수라도 하면? 끔찍하다. - 고객의 외면: 정보 업데이트가 늦어지면 고객은 예약 가능한 방을 찾지 못하거나 잘못된 가격 정보에 혼란을 겪는다.
이런 플랫폼을 계속 쓸 이유가 없다.
결국 RoomAvailability 데이터를 정확하고 빠르게, 자동으로 관리하는 것은 플랫폼 생존의 필수 조건이라 판단했다.
배치(Batch) 도입 배경: '대량' 데이터를 '안정적으로'
숙박 업체가 설정한 정책(RoomAutoAvailabilityPolicy / RoomPricingPolicy)을 읽어서,
시스템이 알아서 미래의 RoomAvailability 데이터를 미리 생성해주면 좋겠다고 생각했다.
왜 하필 배치(Batch) 처리일까?
- 데이터 규모: 숙소 1,000개, 객실 타입 평균 10개만 잡아도 180일 치 데이터는 1000 * 10 * 180 = 180만 건이다.
플랫폼이 커지면 수천만, 수억 건도 우습다. 실시간 처리는 무리다. - 작업 특성: 매일 정해진 시간에 (주로 새벽) 대량의 데이터를 한꺼번에 처리하는 작업에 적합하다.
- 안정성: 대량 처리 중 오류가 나도 중단된 부분부터 다시 시작하거나(재시도), 문제 상황을 기록(로깅)하는 기능이 필수적이다.
Spring Batch는 이런 대규모 데이터 처리, 스케줄링, 안정성 확보 측면에서 가장 적합한 기술이라고 판단했다.
핵심 기능 (간단 소개): 그래서 이 배치는 뭘 하나?
"객실 가용성 자동 생성 배치"는 간단히 말해 아래 작업을 수행한다.
- (Read) 호스트가 설정한 객실별 자동 생성 정책(RoomAutoAvailabilityPolicy)에서 Auto ON으로 설정한(=true) 정보를 읽는다.
RoomAutoAvailabilityPolicy에는 자동 생성 세팅 여부 뿐만 아니라, 자동 오픈 예약 가능 수량, 현재 날짜 기준 어느 기간까지 예약 오픈을 생성할 것인지 설정되어있다. - (Process) 자동 생성 정책이 설정된 객실 타입 기준으로 오늘부터 정책에 설정된 미래 기간(예: 180일)까지 날짜를 하루씩 증가시키며, 해당 날짜에 RoomAvailability 데이터가 없다면, 설정된 정책(예: 기본 가격, 주말 가격, 남은 객실 수 등)에 따라 가격과 예약 가능 개수를 계산한다.
- (Write) 계산된 RoomAvailability 데이터를 room_availability 테이블에 대량으로 쓴다(Bulk Insert).
[RoomAutoAvailabilityPolicy 조회] Read
↓
[정책 기준으로 날짜별 RoomAvailability 생성] Process
↓
[Bulk Insert로 DB 저장] Write
성능 문제 예고: 수백만 건의 쓰기, 버틸 수 있을까?
여기까지 보면 비교적 명확한 작업처럼 보인다.
하지만 진짜 싸움은 여기서부터다.
플랫폼이 성장하여 관리하는 숙소와 객실 수가 늘어날수록,
이 배치가 처리하고 데이터베이스에 써야(Write) 하는 데이터의 양은 엄청나게 증가할 수 있다는 숙명을 안고 있다.
이전에 예측했던 시나리오를 보면 국내 시장 점유율 상위권을 가정했을 때,
하루에 생성해야 할 RoomAvailability 데이터는 최소 100만 건, 많게는 400~500만 건에 달할 수 있다.
매일 새벽, 이 정도 규모의 데이터를 '합리적인 시간 안에' 안정적으로 처리하는 것은 결코 만만치 않은 도전이다.
특히 DB에 수백만 건의 데이터를 빠르게 넣는 것은 생각보다 훨씬 어렵다.
단순히 INSERT 쿼리만 실행한다고 끝나는 게 아니라,
인덱스를 업데이트하고 트랜잭션을 관리하는 등 보이지 않는 비용이 크기 때문이다.
자칫 잘못 설계하면 이 배치 작업이 몇 시간씩 걸려 다음 날 서비스 운영에 영향을 줄 수도 있다.
게다가 이렇게 많은 데이터를 읽고, 가공하고, 쓰는 과정에서 애플리케이션 메모리도 적지 않은 부담을 느낄 것이다.
자바(JVM) 환경에서 대량의 객체를 다루다 보면 필연적으로 GC(Garbage Collection)의 압박이 커지고,
이는 전체 배치 수행 시간을 느리게 만드는 또 다른 원인이 될 수 있다.
과연 현재의 배치 구조로 이러한 성능 문제들을 해결할 수 있을까?
DB 쓰기 병목과 서버 메모리 부담이라는 두 마리 토끼를 어떻게 잡아야 할까?
다음 글부터는 이 배치 Job의 초기 설계(Chunk 방식)가 왜 성능 문제 앞에서 한계를 보였는지 분석하고,
이를 해결하기 위해 Tasklet 방식으로 구조를 변경하며,
최종적으로 DB Insert 성능과 메모리 효율성을 극한까지 끌어올리기 위해
어떤 고민과 실험, 그리고 삽질을 했는지 그 과정을 상세하게 공유하겠다.
(다음 글 예고: "[Batch 시리즈 #2] Chunk 방식? 아니, Tasklet으로 간다!")
'Batch' 카테고리의 다른 글
| [Batch 시리즈 #6] MySQL 옵션 튜닝의 실패, 구조를 향한 시작 (0) | 2025.05.22 |
|---|---|
| [Batch 시리즈 #5] 클러스터드 인덱스를 넘어서: PK 실험과 LOAD DATA INFILE의 만남 (0) | 2025.05.15 |
| [Batch 시리즈 #4] Insert 성능 최적화: PreparedStatement, 그리고 클러스터드 인덱스의 함정 (0) | 2025.05.12 |
| [Batch 시리즈 #3] 성능 측정과 병목점 찾기: Tasklet의 한계, 그리고 Processor 최적화 (0) | 2025.05.07 |
| [Batch 시리즈 #2] Chunk vs Tasklet, 상황에 맞는 최적의 도구는? (0) | 2025.05.03 |